集群由五台broker(Kafka版本2.8.1)组成,上面共有5个topic,__consumer_offsets是50分区2副本,剩余4个topic都是8分区2副本,且所有topic的消息都是没有key的。
最近在巡检kafka集群的时候发现topic的各个分区数据量不是很均衡,有几个分区的数据量明显要大一点。
请问这种现象是正常的吗?
以下是生产者配置(使用spring-Kafka)
producer:
acks: 1
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
linger:
ms: 500
retries: 3
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
以下是消费者配置(使用spring-Kafka)
consumer:
groupId: cmh-kafka-consumer-intercept
properties:
spring:
json:
trusted:
packages: com.ponshine.entity
session.timeout.ms: 30000
request.timeout.ms: 5000
max.poll.interval.ms: 600000
fetch.min.bytes: 1024
fetch.max.wait.ms: 2000
enable-auto-commit: true
auto-commit-interval: 2000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
max-poll-records: 1000
fetch-max-wait: 1000
listener:
concurrency: 2
missing-topics-fatal: false
poll-timeout: 3000
type: batch
以下是分区数据不均衡的截图:
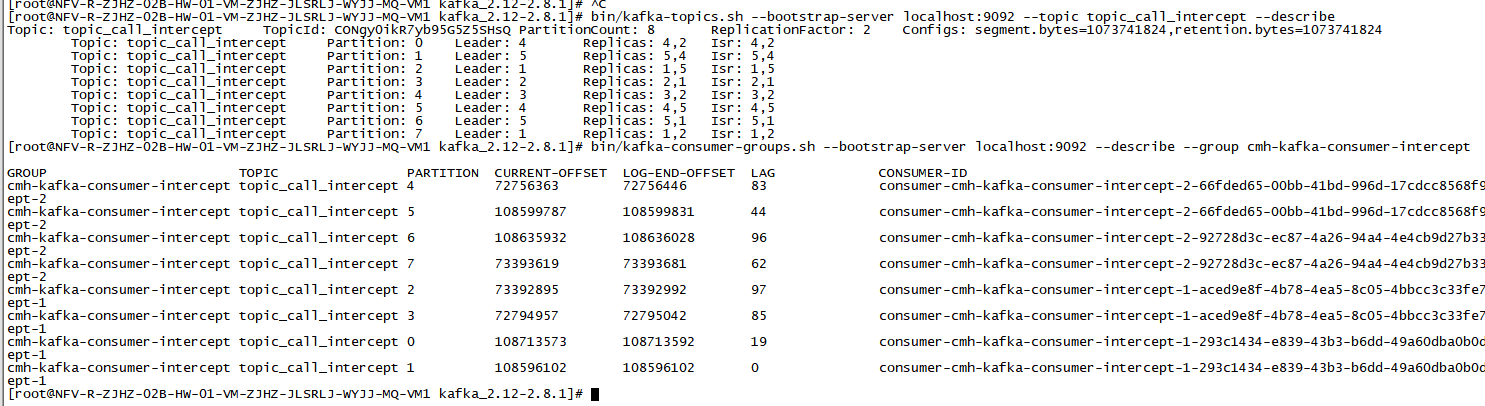




你没设置key,所以kafka消息发送是轮询批量的方式发送到各个分区。
消息的差异是日积月累产生的,平均到每天的话并不大,可以忽视。
不平均要从生产者源头确认,举个例子,你有
8个分区,生产者是轮询的发送,消息并不是立即发送,而是打包到一个批次后,一起发送到第一个分区,但是什么时候发送受2个参数batch.size和linger.ms的影响,就是消息大小达到1M或者0.1秒了,就立即发送。基于以上的逻辑,推测你的客户端,产生的消息量并不是平均的,所以每次轮询推送到这些分区的消息批次,正好少那么一些。
你的答案